AI・テクノロジー
スマートグラスは、ユーザーの認知負荷を読み取れるのか
Takahiro Hamaguchi
2026年5月27日・12分で読める
@t_hamaguchi
日本メディカルAI学会所属 愛媛県の調剤薬局で働く薬剤師です。 薬剤師が自信を持ってAIを活用するためのWebサイト「薬剤師のためのAIノート」の管理者です。 noteの記事は「https://note.com/pharma_i_cist」からどうぞ。 <資格等> 日本薬剤師研修センター 研修認定薬剤師 日本メディカルAI学会公認資格 基本情報技術者試験合格 JDLA G検定 2024#5 <修了プログラム> Google AI Essentials(Coursera) IBM Data Science(Coursera) Google AI Professional(Coursera)
*元論文:Wang, B et al. (2026). GazeMind: A gaze-guided LLM agent for personalized cognitive load assessment.
今回の研究は、スマートグラスから得られる視線データを使って、ユーザーの認知負荷を推定するAIエージェント「GazeMind」を提案したものです。
ここでいう認知負荷とは、タスクをこなすときに必要になる精神的な労力のことを指します。たとえば、文章を読む、暗算をする、相手の話を聞きながら判断する、複数の情報を同時に処理するといった場面では、認知負荷が高くなります。
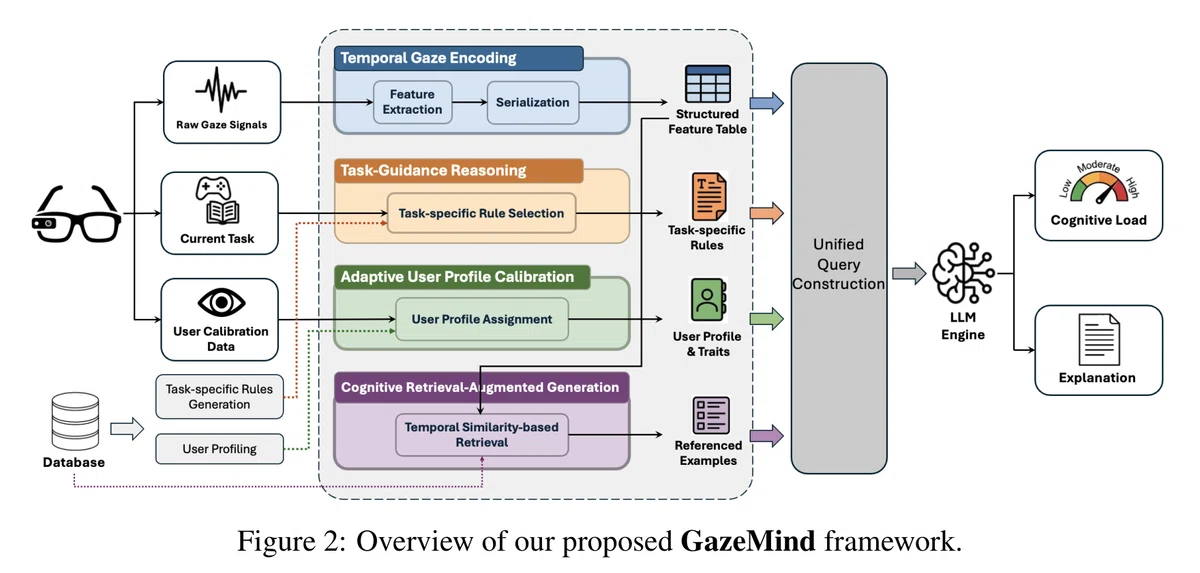
Figure 2:GazeMindの全体像(出典:Wang, B et al. (2026). GazeMind: A gaze-guided LLM agent for personalized cognitive load assessment.)
GazeMindは、主に以下の4つの要素で構成されています。
4つの要素を組み合わせることで、GazeMindは「なぜその認知負荷と判断したのかを説明できるAIエージェント」として機能できるようになっています。
今回の研究では、「CogLoad-Bench」という新しいデータセットも作成されており、参加者152名、録画456件、40時間以上のデータ、1万件以上の正解ラベルが含まれています。
タスクは、以下の3種類に分かれています。
認知負荷は、タスク中に15〜30秒ごとに参加者が口頭で自己申告しました。もともとは7段階評価でしたが、最終的には「Low」「Moderate」「High」の3段階に統合されています。
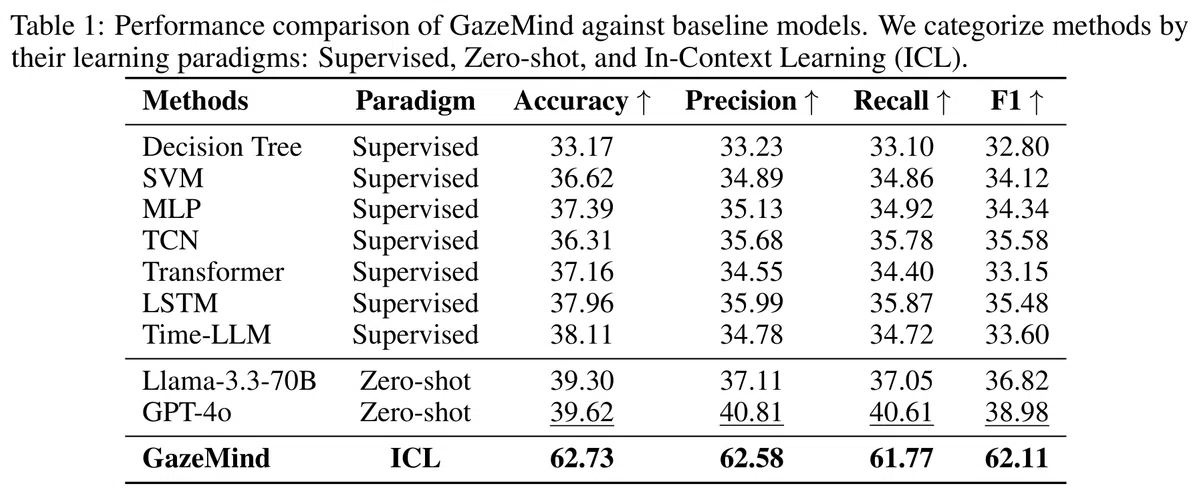
Table 1:GazeMindと既存手法との比較(出典:Wang, B et al. (2026). GazeMind: A gaze-guided LLM agent for personalized cognitive load assessment.)
GazeMindは、Accuracy:62.73%、F1スコア:62.11%を達成し、既存手法のスコアを上回る結果となりました。
この結果から、視線データをLLMが扱いやすい形式に変換し、タスクの情報、個人差、過去の類似の事例を組み合わせてLLMに渡すGazeMindのアプローチによって、精度の改善が期待できることが示唆されました。
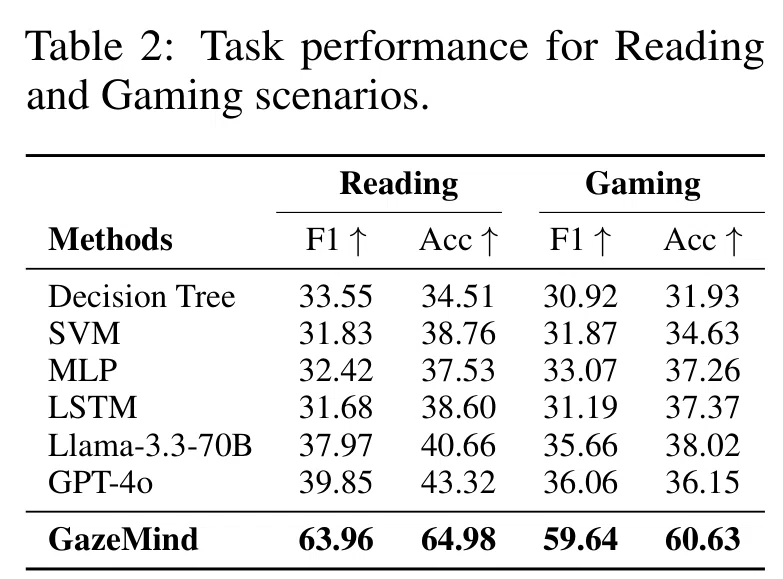
タスク別に見ると、
このような結果となり、著者らは「読解・推論の課題の視線パターンは比較的安定している一方で、ゲームの課題では環境的な妨害や動きの要素が多いため、それがスコアに影響を及ぼした可能性がある」と解釈しています。

Table 3:各要素を追加していった時の性能変化(出典:Wang, B et al. (2026). GazeMind: A gaze-guided LLM agent for personalized cognitive load assessment.)
Table 3では、CogRAGを加えた段階で大きくスコアが改善していることが示されており、類似する過去の事例をLLMに提示することが、判断の質の改善に大きく寄与する可能性があることが示唆されました。
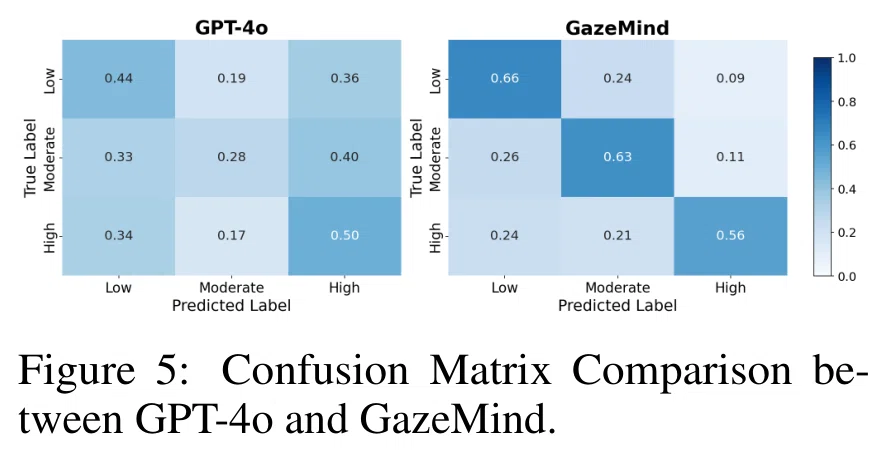
Figure 5:GPT-4o単体とGazeMindを比較した混同行列(出典:Wang, B et al. (2026). GazeMind: A gaze-guided LLM agent for personalized cognitive load assessment.)
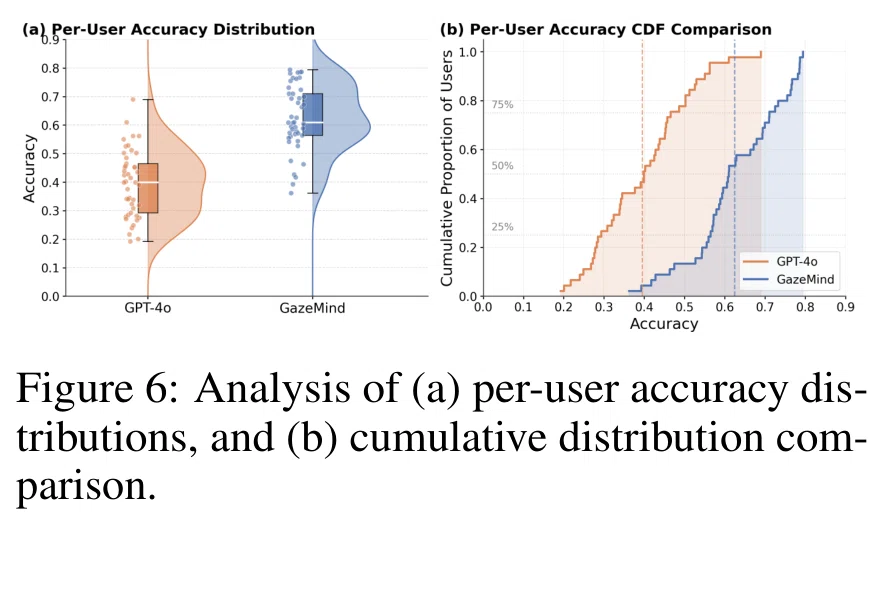
Figure 6:ユーザーごとのAccuracyの分布(出典:Wang, B et al. (2026). GazeMind: A gaze-guided LLM agent for personalized cognitive load assessment.)

Figure 7:ケーススタディ(出典:Wang, B et al. (2026). GazeMind: A gaze-guided LLM agent for personalized cognitive load assessment.)
著者らは、GazeMindはGPT-4oと比較して、Low、Moderate、Highの3段階に対してよりバランスの取れた予測を行ったと説明しています(Figure 5)。
また、Figure 6にユーザーごとのAccuracyの分布が示されていますが、GPT-4oでは多くのユーザーが40%未満にとどまる一方、GazeMindでは多くのユーザーが60%以上のAccuracyを達成していることがわかります。
これは、AUP(個人の特徴を踏まえた判断)による個人差への対応が一定程度うまく働いたことを示唆しています。
加えて、ケーススタディ(Figure 7)も見てみると…
このように、個人差に一定の配慮がなされていることが示唆されました。
2026年5月時点において、恐らくほとんどのスマートウォッチやスマートリングは、ユーザーの健康に関する様々なデータを収集・記録ことが可能になっていると思われます。
例えば、Apple Watchであれば…
少なくともこれらのデータを収集・記録することが可能です [1] 。
一方で、スマートウォッチやスマートリングは医療機器ではありません。
収集したデータが正確である保障はありませんし、そもそもメーカー側が意図した使い方から逸脱していた場合は、測定の質が大きく低下します。
健康に関心を持つことはもちろん大事なことなので、これらのデバイスで情報を毎日記録すること自体は良いことだと思います。ただし、その情報を過信して自己判断をすることは避けたほうが良いでしょう。
前提として、スマートグラスの場合でも先ほどと同様のことが言えます。
今回の研究では、現実的なデータ品質の揺らぎを想定して「視線データが一部欠けた場合でも、GazeMindがどれくらい正しく判定できるか」が検証されていますが、データが欠けていない場合のAccuracyは62.73%であったのに対し、データの30%が欠けると56.94%、50%が欠けると47.54%まで下がりました。
そもそもデータが欠けていない場合のAccuracy:62.73%も十分な正確さとは言えませんが、スマートグラスの装着のずれ、測定ミス、環境の違いなどによって、さらに精度が低下する可能性があることは、頭にとどめておかなければなりません。
加えて、スマートグラスは本人の視線だけでなく、周囲の人や環境に関する情報も保存できると考えられるため、プライバシーには特に注意が必要です。
特に、本人が「何を見ているか」「どこで迷っているか」「どの場面で負荷が高いか」などといった情報は、個人の行動や心理に関わる、非常にセンシティブなデータになり得ます。
極端な話、スマートグラス内には「ユーザーの普段の様子がありのままに記録されている」と考えておいたほうが良いでしょう。
今後日本でもスマートグラスが普及してくるかもしれませんが、スマートウォッチやスマートリングとは異なる、スマートグラスならではのリスクが存在することを忘れてはなりません。
[1] Apple Watchユーザーガイド「Apple Watchのヘルスケア機能を使ってみる」
https://support.apple.com/ja-jp/guide/watch/apd7941a2f19/watchos


